
Opened 8 years ago
Closed 5 years ago
#67 closed defect (fixed)
trap D (version 326)
| Reported by: | Barry Landy | Owned by: | |
|---|---|---|---|
| Priority: | major | Milestone: | Future |
| Component: | IFS | Version: | |
| Severity: | medium | Keywords: | |
| Cc: |
Description
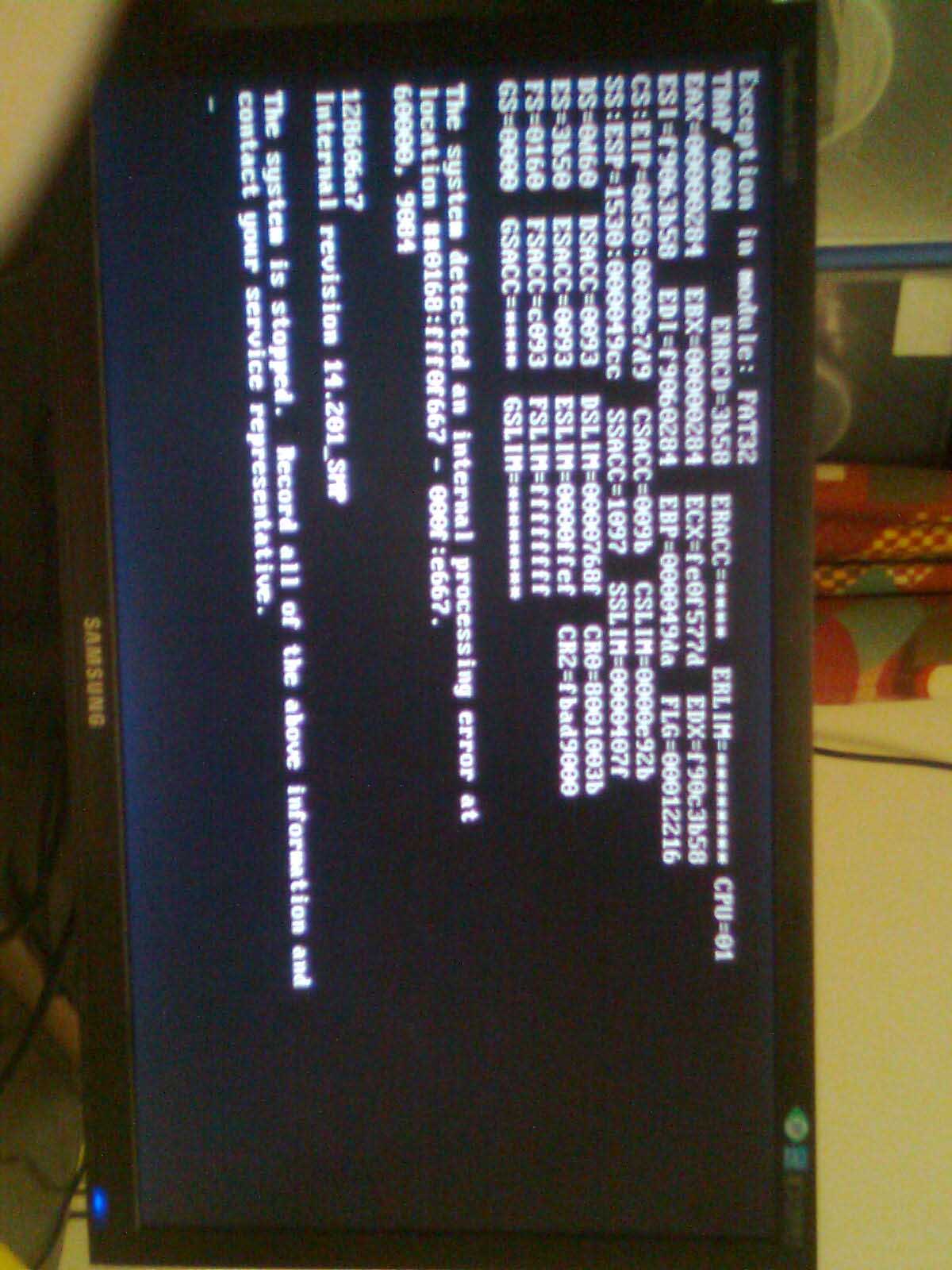
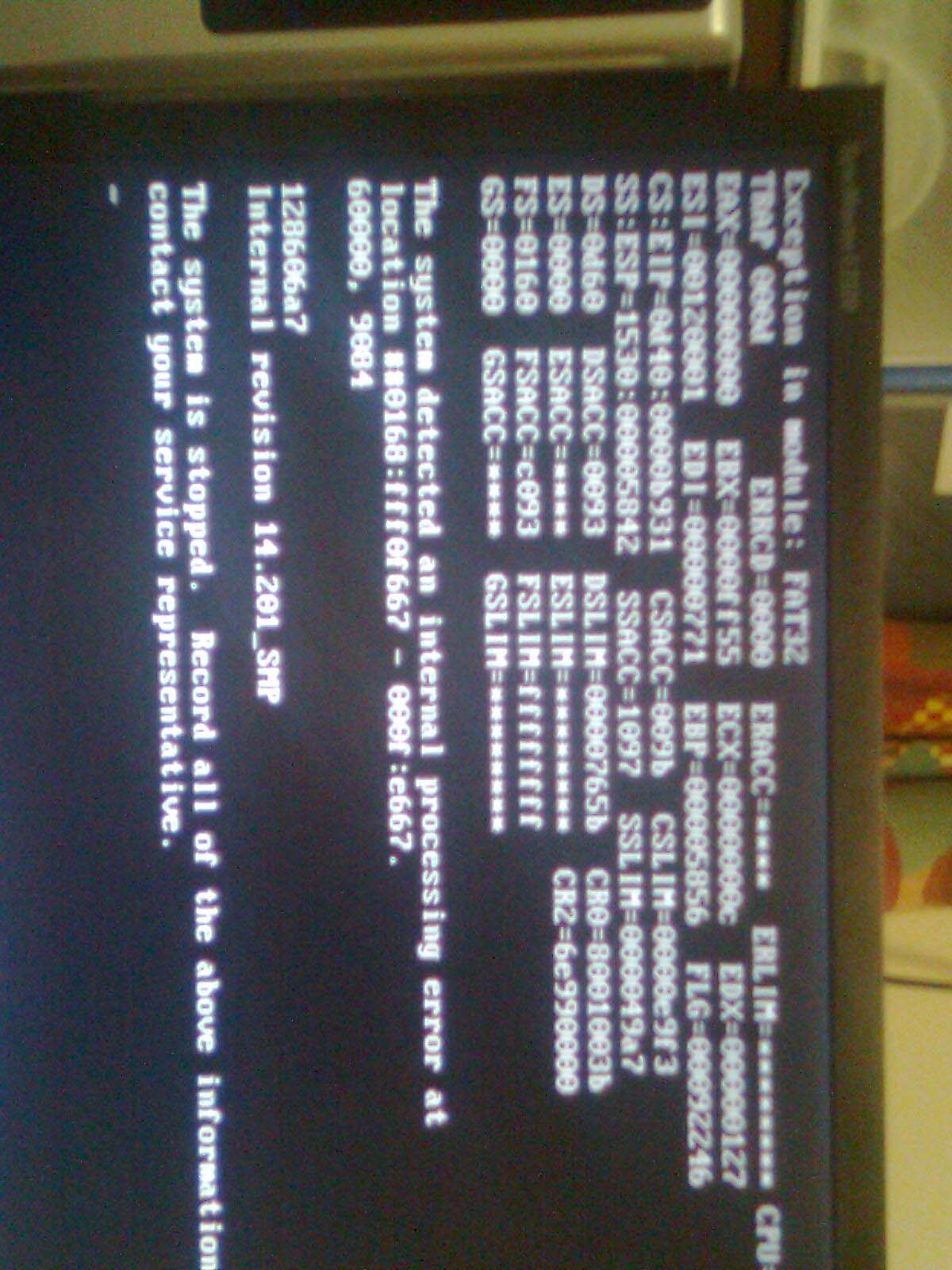
Editing a file on a FAT32 volume initiall gave an error 6, and then when exiting the DOS window, a trap D
The only data I have is a picture of the trap screen (somewhat blurred with apologies).
I do not know if it is reproducable; among other things the file I was editing vanished (I presume the CHKDSK on reboot removed it) and I had to recover it from a backup.
I backed off to version 290, and everything seemed OK.
SYSTEM: ArcaOS, nucleus 201
Attachments (36)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (158)
by , 8 years ago
| Attachment: | Image0191s.jpg added |
|---|
comment:1 by , 8 years ago
comment:2 by , 8 years ago
2Lars: So, you think, it is the same problem like #65? The same trap screen?
2landb: As far as I can see, it traps somewhere in free() function. Too little info to see where free() got called. But maybe, Lars is right, so it won't hurt to update to the latest version and see. The latest version in r330.
PS: r330 contains new cool feature added. Now you can mount file system images with FAT12/16/32/exFAT to a subdirectory on a FAT12/16/32/exFAT drive. Image files can lay around on any filesystem, but a mount point should be on a FAT filesystem (otherwise, fat32.ifs could not change to the mounted filesystem). Volumes can be mounted via new f32mount command. Support for reading data from virtual machine images (raw/qcow/bochs/parallels/vpc/vmdk/dmg/cloop/vvfat) is added to f32mount and cachef32 (ported from QEMU). So, fat32.ifs now calls cachef32 to read/write the images. Diskette images are supported too. The image support is implemented completely in user mode. Also, I implemented CHKDSK/FORMAT/SYSINSTX support on images, mounted to a subdirectory. (Still some problems exist, but it mostly works.). You can try this new feature.
comment:3 by , 8 years ago
R330 seems fine. Repeated the same activity without problem. I have not tried any new features....
comment:4 by , 8 years ago
My mistake.....
There were no traps but I have just noticed that the dataset I was editing has vanished (now recovered from backup!)
comment:5 by , 8 years ago
2Valerius:
sorry that I confused things. The trap happened in #64. The trap screen in #64 is different but it is with SVN rev 325 whereas in this ticket we are talking about SVN rev 326. We already know where the trap happens in ticket #64 (reading an invalid address for the Capabilities pointer) and it likely is a different error.
Anyway, since svn rev 330 is now working ok for Barry I very much assume that reverting the change done in svn rev 324 ("read FAT16/32 in 32k portions") fixed it for Barry just as it did for me.
I guess we can close this ticket.
comment:7 by , 8 years ago
2landb: So, with r330 it does not trap, but file still gets vanished? Can you take a log with f32mon (Start it before launching your DOS editor)?
comment:8 by , 8 years ago
OK I tried using 330 again with F32MON.
Unfortunately at the end of the process (editing a dataset) there was another trap D. Photo attached. That meant I lost the F32MON data.
In addition the file I was editing was lost. in its place was a zero length file called xxxxxx.BK! (xxxxxx being the original name)
by , 8 years ago
| Attachment: | Image0192.jpg added |
|---|
comment:9 by , 8 years ago
Again falling in free(), so nothing changed. No further info. You'd better buy a null-modem cable and show me the COM port log (or help me to reproduce your problem on my machine). Otherwise I could hardly help you.
Maybe, also, this is a uninitialized variable somewhere. I fixed some uninitialized variables in r331, so please try it first! (It is at the usual place, where the builds archive resides).
comment:10 by , 8 years ago
Will try 331. I already have a null cable and all the code necessary to use a second computer as a monitor (in connection with problem 47)
I misrepresented what happened to the dataset
X became X.BK! (presumably the editor making a copy while updating) with the old contents. After the trap D there was no sign of X I tried copying the original (which I had securely stored elsewhere- not on FAT32!) onto the FAT32 volume and it would not store as X (appeared to work but no sign of it throu the DIR command). I had to store X as X.NEW and then rename and then all was fine.
comment:11 by , 8 years ago
I get a trap D also from 331
When I run with cable modem and debug nucleus I assume you would like me to run D32mon?
As well as this problem I also have a chkdsk problem (I will open a new ticket)
comment:12 by , 8 years ago
Null cable; using PUTTY as a monitor
1) Putty01: no trap D but at then end of the edit process the file being edited had vanished Name of the file is D:\d\notes\os2\histdq67 (D: is formatted FAT32)
by , 8 years ago
| Attachment: | putty01.txt added |
|---|
comment:13 by , 8 years ago
I have not so far managed to get a trap D again, but losing a dataset is bad enough!
comment:15 by , 8 years ago
Sorry: I dont understand that comment.
I have given you a F32MON trace of a sessi nwhich resulted in the directory pointer to a dataset vanishing. Do you need more data?
comment:16 by , 8 years ago
Barry, I have addressed the comment to Valerius. There is a bug in the combination of dynamically allocating and freeing memory. I suspect that once that problem is fixed that that might help with your trap D / data loss.
I expect that problem to fire at the moment where you unplug or eject a USB stick, for example.
comment:17 by , 8 years ago
2landb: Which file did you edited? D:\DELETE\CONTROL.DEL? I see no attempts to open D:\d\notes\os2\histdq67 in your log. Did you opened it earlier than started f32mon? Please, start f32mon before you start editing anything. Also, I don't see here any function returning ERROR_INVALID_HANDLE == 6. Are you sure this is not your program is vanishing this file? I see no errors from fat32.ifs. What did you do that the file is vanished? (the exact sequence of actions?).
And please, take a log of a trap 000d first. Then we'll try work out the file vanishing.
2Lars: I doubt that this problem is related to pDevCaps, as it is occurring not on mount/unmount, but when editing the file.
comment:18 by , 8 years ago
free() is calling freeseg() under the hood, so, there is no difference in calling free() or freeseg(). But yes, probably it will look more clear to use freeseg(), as opposed to gdtAlloc(), so I agree here. I doubt that is somehow related with #67, though.
comment:19 by , 8 years ago
Sorry, previous message was intended to ticket #65, so, please, ignore it here.
comment:20 by , 8 years ago
As I said before I was editing D:\d\notes\os2\histdq67
I started F32mon well before opening the dataset. The program I am using is wordperfect for Dos. it works perfectly well. If I use version 290 the editing completes correctly and the file doesnt vanish.
I have found a FAT32.LOG on my drive which shows clearly an opening of the HISTDQ37 file; of course it is far too big to post here.
I will: 1) run version 290 to get a trace of opening and closing the dataset3 2) run version 331 until I get a trap D (seems to take several efforts).
by , 8 years ago
| Attachment: | v290open.txt added |
|---|
by , 8 years ago
| Attachment: | v290close.txt added |
|---|
comment:21 by , 8 years ago
F32mon puts out lots of data and significant information can get lost "off the top"
I have run the editing process in version 290
V290open shows HISTDQ67 being opened
V290close shows HISTDQ67 being closed (I had to increase the number of lines in PUTTYs buffer to get enough data)
by , 8 years ago
| Attachment: | v331open.txt added |
|---|
by , 8 years ago
| Attachment: | v331close.txt added |
|---|
comment:22 by , 8 years ago
I have run again the editing process in version 331
V331open shows HISTDQ67 being opened
V331close shows HISTDQ67 being closed
Oddly, the system died where the last log stops. No trap, just unresponsive system. Will keep trying for a trap.
comment:24 by , 8 years ago
.. and even when the process seems to work correctly the file is either zero length or missing altogether.
by , 8 years ago
| Attachment: | v331closeA.txt added |
|---|
by , 8 years ago
| Attachment: | v331closetrapd.txt added |
|---|
by , 8 years ago
| Attachment: | Image0193.jpg added |
|---|
comment:25 by , 8 years ago
I finally got the trap again.
First the WP process said ERROR 6 and I could see on the log an error 2 shows
V331closeA shows the F32MON log at this point (and shows an error 2)
I then continued and the system trapped: V331closetrapd is the log
picture on my phone of the trap screen is image0193.jpg
comment:26 by , 8 years ago
I will very shortly be in a position to resume trying to catch this trap. So it would be a good time for you to now look at my F32mon logs and see what you can find or what tracing to insert.
comment:27 by , 7 years ago
Hullo! Anyone there?
This problem is still present. Since it causes both data loss and trap D I think it should be investigated.
Meanwhile I see that there is a new version on the Netlabs site, so I tried version 336.
Unfortunately this failed to boot (two attempts); it stopped somewhere at the end of Config processing and before the WPS was set up.
It would probably take the tracing to see where, possibly with a debug version. I will do that if the developer will look at it.
comment:28 by , 7 years ago
Hi, yes, I'm free for some investigation.
Unfortunately this failed to boot (two attempts); it stopped somewhere at the end of Config processing and before the WPS was set up.
Where did it stopped? cachef32.exe trapped? Please look for POPUPLOG entries, if any, and show me a COM port log (add a /monitor switch to a command line).
It would probably take the tracing to see where, possibly with a debug version. I will do that if the developer will look at it.
Yes, of course, will look at it.
comment:29 by , 7 years ago
Will do.
Meanwhile it occurred to me to ask if it would be sensible to reformat the partition. It was formatted way back in the mists of time and possibly there were bugs/infelicities in the way it was formatted?
comment:30 by , 7 years ago
Reformat why? I don't know about any bugs in FORMAT code that may cause creation of faulty partiotions. I did not changed FORMAT code much, so far, if you mean that. But your partition may be broken because of different other causes. So, you may try reformatting it, of cause, if you think that the trap is because of a broken FS. Maybe, it will help.
But I mostly wonder very much, why your system does not boot ok with version r336. I did nothing which can cause fail to boot. I only changed the code related to the new feature of mounting file system images (e.g., floppy images, or VM images). I did not touched code related to reading or mounting ordinary partitions.
How does it not boot? A system trap? Or a trap on cachef32.exe? Hang when cachef32.exe is booting?
comment:31 by , 7 years ago
I only asked about formatting as I saw a comment somewhere about incorrect formatting causing problems. Lets forget that.
The boot simply stops so possibly a hand in cachef32 which is the last item I see. I will get data.
comment:32 by , 7 years ago
Various things to report
1) when the boot stops the last line on the screen is the translate table message from CACHEF32
2) When I run the debug kernel and use my T61 as a terminal the boot process completes normally (!)
3) However it then stops with a trap 1 before initialising the WPS (which is normal). However I do still have kdb.ini setup with the right data in it so it ought to proceed but doesnt.
4) If I type G to make it proceed the system initialised normally AND I can confirm that the problems observed in R331 are also present in R336. I have not so far generated a trap (that is harder to do) but I can generate the dataloss issue and also the incorrect read from IBMWORKS.
I assume you would like a trace using F32MON?
by , 7 years ago
| Attachment: | v336pim.txt added |
|---|
comment:33 by , 7 years ago
Various confusing experiments
1) With the normal nucleus R336 stops (as above) at the message from CACHEF32
With the debug nucleus it does not stop there but carries on to the trap 1; the "g" in kdb.ini is not read but typing g to the terminal monitor causes the system to proceed
2) With the normal nucleus R290 initialises as normal
With the debug nucleus R290 stops at the messages from CACHEF32
so I assume there is some timing issue.....
3) After starting R336 (debug nucleus) I started F32mon and tried to call the IBMWORKS addressbook. This failed quite quickly and gave a blank database; the attached file V336pim.txt is the log.
Doing the same for R290 normal nucleus with F32mon was quite different; it took a very long time and was (from the log) reading block after block of the database. The log at that point doesnt seem to be valuable.
To make progress:
a) is the attached log helpful in seeing why the IBMworks addressbook doesnt initialise? If so, lets fix that and move to the other problem.
b) any ideas re the timing issue? the inability to boot makes experiments difficult.
comment:34 by , 7 years ago
Ok, let's start from the last problem you have -- hang on cachef32.exe boot. We need to work problems out one by one, not all at the same time. So, please, take a log when booting, until the hang. (add the "/monitor" switch to fat32.ifs and see). Also, please, put your config.sys here. Also, your kdb.ini and your kernel versions, both debug one, and retail one.
I tried both the debug OS/4 kernel, and retail 14.200 from arca noae -- both not hanging during the boot. So, I cannot reproduce your hang on my machine, so far.
Wrt. the trap 1, it's probably wrong settings in kdb.ini or config.sys. Also, I'd like to see this trap, better in the COM port log (or, a screenshot, if it's not possible). But better a COM port log, where I could see both the trap screen and the preceding messages.
comment:35 by , 7 years ago
totally agree; one thing at a time.
I am testing with ECS22 and using qsinit to switch between normal nucleus and the debug one. normal Nucleus: 14.106 (30/5/13) debug nucleus: came with the ECS22 install CD, dated 18/7/09
kdb.ini is unchanged from when we were debugging last June; I attach it to this problem.
Config.sys is rather complicated and I have also attached it. I will take a com port log and attach it.
by , 7 years ago
| Attachment: | config.sys added |
|---|
by , 7 years ago
by , 7 years ago
| Attachment: | r336_hang.txt added |
|---|
comment:36 by , 7 years ago
R336_hang is the hang in config processing in the call to cachef32
NB in this boot I had the /monitor switch set for the call to FAT32.IFS. However with that set all attempts to boot hang at this point.
by , 7 years ago
| Attachment: | r336_trap1.txt added |
|---|
comment:38 by , 7 years ago
What is the disk C:? What filesystem? It looks like it hangs on attempt to unmount it, during remount.
Trap 1 seems to be unrelated to fat32. It occurs when loading the video driver (VMAN.DLL).
comment:39 by , 7 years ago
It is formatted FAT32. It's purpose it to be the boot volume for windows but to permit the large windows partition to be logical rather than primary
I dont think the OS2 systems use it (though they obviously give it a drive letter C:)
In the sense that if I type g the system continues the trap1 is not critical but it is odd.
comment:40 by , 7 years ago
Yes, very strange how it reacts to your disk C:, It mounts it successfully, Then remounts it, and finally tries to unmount the previous mounted version, and hangs here. I never seen this on FAT32 drives.
So, please try this version: ftp://osfree.org/upload/fat32/test/bl1.zip. (add the /monitor switch). Also, better use OS/4 kernel (it has more verbose output which can be helpful to me). Add it to your QSINIT config file.
comment:41 by , 7 years ago
Will do. I have OS4 kernel set up from the June experiments.
Just BTW this setup is a relic from long ago, dual booting OS2 and windows (3.1). There had to be a C: for windows and the D: (DATA) as a second primary and then E: (first logical) as boot for OS2 using bootmanager. PRE LVM days..... and of course what there was, remains...
by , 7 years ago
comment:42 by , 7 years ago
OK. file RBL1.txt contains what looks like a stop in the same place using OS4 debug kernel (with OS2APIC in place of ACPI and with /monitor)
by , 7 years ago
comment:45 by , 7 years ago
Ok, good. Now please, the same with bl3.zip (at the same place).
PS: Are you sure BTW, that your disk C: is in good condition? Did you checked its SMART status, at least? I see it hanging when trying to read sectors from disk C:, when unmounting. I saw similar errors on FAT32 flash stick, attached via a faulty USB controller (integrated one). It works fine through another USB controller, which is in good condition (installed as a PCI extension board). I'd suspect that it may be faulty IDE drive. Though, I need to check last hypothesis with bl3.zip test.
PPS: All of my three IDE drives has been died recently. The most older was a 80 GB seagate barracuda, which was since about 2003. Your disk seems to be even older (you said, it is since Win 3.1 times).
by , 7 years ago
comment:46 by , 7 years ago
RBL3.txt; same test.
You misunderstood. The configuration is from win3.1 days, the hardware has changed many times. Most recently I changed from PATA (IDE) discs to SATA and then to SSD.
I havent checked recently but nothing seems to have complained.
The ECS system I am using to test is booted (drive E) from the same disk as C: - might this be relevant?
comment:47 by , 7 years ago
So, this is SSD? As far as I can see, it hangs on reading sectors. So, something is bad with your disk. Probably, it has bad sectors. Spare sectors pool may be exhaused. So, you need to check your disk SMART status. It may show something. As I mentioned previously, I've seen this on a good flash disk, but with dying USB controller. Also, I seen this on my dying IDE disks. When I replaced them with newer SATA disk, all resolved. Also note that newer disk serve much less time, than old smaller disks. The quality is much degraded since older times. It is just harder to make bigger disks with the same quality. Many newer smaller disks are just bad quality higher capacity disks (defective planes or tracks are just disabled). I had a 80 GB disk, which served me over 15 years, but newer disks are dying much quicker -- in several years. Something is indeed bad, the disk, or the controller.
Also, your JFS partition could be free from bad sectors, but C: one is faulty.
Also, fat32.ifs reads sectors via FSH_DOVOLIO API. It just blocks when faulty sectors are read. JFS uses strat3 routine directly. It may behave better, so JFS may not block on bad sectors. I had JFS disk with bad sectors, and I experienced traps, not hangs when reading such sectors. Or it may not even trap, just return an error. So, things may differ.
comment:48 by , 7 years ago
I will use DFSEE to look for bad sectors on that disk
NB remember that version 290 of FAT32.IFS works fine......
comment:49 by , 7 years ago
Please try bl4.zip now. I changed one flag for FSH_DOVOLIO function -- it looks it can be instructed to return error, instead of block, but we need to try. It will not fix your disk completely, but at least should not block.
PS: I don't know why r290 does not block for you. The call to FSH_DOVOLIO was the same, and I changed nothing related to this. So, I have no ideas.
comment:50 by , 7 years ago
DFSEE finds no bad sectors and Chrystaldiskinfo says all my SSDs (3) are fine.
It doesnt like an external USB connected drive but that shouldnt affect anything....
by , 7 years ago
comment:52 by , 7 years ago
Hangs again? Very strange, as it should return an error. Are you sure you used bl4.zip?
comment:53 by , 7 years ago
Try bl5.zip now. It now should ask "Abort, retry, fail?" on errors (unless AUTOFAIL=YES is specified on CONFIG.SYS)
comment:54 by , 7 years ago
yes, date and length of FAT32.IFS in testing system match BL4
I realise that I(as I said above) I have a USB connected drive which does have FAT32 partitions on it. I will try booting with it switched off as well as on to see if it makes a difference.
comment:56 by , 7 years ago
RBL5a : boot as before and still hangs after the chachef32 call
RBL5b : boot as before with the external USB drive switch off. No apparent difference.
both hang; neither gives a message "Abort retry fail?"
by , 7 years ago
by , 7 years ago
comment:57 by , 7 years ago
Very strange that this didn't fixed blocking on FSH_DOVOLIO for you. I tried bl5.zip on my machine, and it seems, it fixed hanging on FSH_DOVOLIO on faulty USB controller. Now I was able to copy 4 GB of data to my flash stick, and back. I tested data integrity -- all were ok (I used .zip archives and verified their integrity successfully). I will test more, of course, but previously I could not copy 100-200 MB of data without an error. Now I successfully copied 4 GB. Probably, I had only temporary errors, which could be resolved with retries, so all copying went ok. You could have bad sectors. I'd adice you to test it more thoroughly. Did you tested SMART parameters? You can try utilities like MHDD or Victoria to test the surface and SMART parameters -- maybe, it'll show something. I tried to test my faulty IDE drives with DFSee -- it won't find anything, but the drives were still faulty. I heard beeps on speaker during attempts to read/write to these drives. This is DaniS beeps on I/O errors. Do you have PC Speaker on your machine? Did you heard any suspicious beeps?
PS: I have AUTOFAIL=YES enabled too. So, it should return an error silently. With AUTOFAIL=NO, it should show the "Abort/Retry/Fail?" dialog. For Abort/Retry/Fail? popups, you should also disable SUPPRESSPOPUPS=<driveletter>. Otherwise, popups should go into POPUPLOG.OS2.
PPS: Attaching the USB drive should not matter, because USB drives aren't mounted on boot. You should do RediscoverPRM manually for them, to be mounted. So, attaching or detaching USB drives is not important.
comment:58 by , 7 years ago
I dont have any IDE so I dont have DANIS any more and I dont have any beeps.
I can ask DFSEE to do a read/write scan.
I also have MHDD and can try that, but I remain unconvinced that there is a dormant hardware issue.
(and in any case this hang is not the reason I opened this problem)
comment:59 by , 7 years ago
I dont have any IDE so I dont have DANIS any more and I dont have any beeps.
OS2AHCI may beep too, but I didn't used it, so far, and I am not sure. DANIS can beep with SATA drives, as well. So, you could try to change OS2AHCI to DANIS temporarily, to see the difference.
I also have MHDD and can try that, but I remain unconvinced that there is a dormant hardware issue.
It looks to be an hardware issue, because I don't see any reason to hang on sector reads, except for bad sectors, or faulty hard disk, or controller hardware.
(and in any case this hang is not the reason I opened this problem)
Yes, this not the current ticket topic. But it blocks you from going to test further with the main problems. So, if you'd like to postpone this problem, and go to the main one(s), I'd suggest you to remove the LVM info from disk C: temporarily (you can do that with DFSee, just delete the explicit drive letter there, and leave it empty). Then it will not be mounted, and hang during the boot could be avoided.
comment:60 by , 7 years ago
yes, I can do that. I dont even think I use the contents of that partition in OS2 any more. There are other partitions on the drive that I definitely DO need with OS2, so perhaps it would be an even better test.
comment:61 by , 7 years ago
OK I removed the C: from that partition. I also put back R336 for the moment.
System still hangs, and R336_newhang is the log.
by , 7 years ago
| Attachment: | r336_newhang.txt added |
|---|
comment:62 by , 7 years ago
Yes, the same with N:, as it was with C:. So, N: is FAT32 too? Is it on the same physical hard disk as C:? If you'd remove drive letter N: (just for test), will it hang on another drive?
comment:63 by , 7 years ago
PS: I don't see the debug messages I added in bl5.zip on disk N:. Did you returned the old IFS back? If so, please retest with bl5.
comment:64 by , 7 years ago
1) yes N is FAT32 BUT it is on the second of my 3 SSD's. I really dont believe that has hardware erros also.
2) yes I can remove that drive letter (and another on the same SSD)
3) I re-did the test with BL5. log is in RBL5c
by , 7 years ago
comment:65 by , 7 years ago
I removed two drive letters from the second SSD (N: and P:). There remain however two that I need (D: and S:)
In that state ECS22 boots successfully.
If the SSD is faulty why dont we have the same problem with D: and S:?
Anyhow in this state we ccould chase the original problem(s)
comment:66 by , 7 years ago
Just to let you know. I have managed to damnage the hard drive on my laptop and it will take me a little while to recover it (this evening if I am lucky!). Until then I cannot do tests that involve logging.
comment:68 by , 7 years ago
1) Thinking about your claim that the SSD is giving errors I downloaded the Kinston SMART monitor.
It says : failures none : warnings none : status healthy
2) until trying to produce a log by running the debug kernel there were no hangs in the config processing. Seems like an artefact or a timing problem.
3) I am slowly moving to being able to replace the Kingston by a Crucial SSD.
by , 7 years ago
| Attachment: | RBL5cruc.txt added |
|---|
comment:69 by , 7 years ago
I have done an experiment with the Crucial. Exactly the same layout as before BUT with the drive letter C restored to the winboot partition. Booted with OS4 debug kernel. System initialises notmally. BL5CRUC.TXT is the trace showing correct response from C:\.
Unfortunately I cannot leave this system connect at present as the windows system is claiming it is a pirate system and I have to sort that out before I can use it......
comment:70 by , 7 years ago
So, it looks like another SSD behaves different. The older one may be not too faulty indeed, but just generate some errors on some drives, while Crucial SSD does not, and everything is ok. So, as far as I can understand, when reading/writing sectors, FSH_DOVOLIO just blocks when some read/write error is encountered. So far, I don't know how could I handle this. I tried to reproduce the problem on my machine with my "faulty" integrated USB controller, which has similar problem on USBMSD devices. On second, external, USB controller, these errors are missing. So, for the 1st time, I changed some FSH_DOVOLIO flags, and it seemed that it helped. I was able to successfully copy 4 GB of data, without errors (with "faulty" USB controller). But when I did additional attempts, it finally hanged. So, it did not fixed to me, too. So far, I have no ideas, how could I handle this, but I need to think. Maybe, there are some other flags to try. I need to experiment with an USB controller on my machine first.
PS: Sorry for being slow to answer. Unfortunately, I now got a job offer, so I need to handle with it. But still I expect to resume working this problem out soon.
comment:71 by , 7 years ago
not to worry, and good news on getting a job.
I am still trying to have a successful clone of SSD1 to SSD2 (success = working windows). experiments take a long time... I am currently waiting for a repeat of the clone to finish.
comment:72 by , 7 years ago
The replacement Crucial SSD is now fully in service..... (and the reported state is better than the Kingston)
by , 7 years ago
comment:73 by , 7 years ago
Chasing one problem: IBMworks does not initialise properly
FAT32 R336 with BL5 unzipped on top FAT32.IFS/monitor OS4 debug system
pim01.txt is the trace of the failure to open the ibmworks database correctly (the application shows an empty database). To find the relevant places search for "pim" or "pim\now"
(I can see various return codes of 2 if that is signoificant)
by , 7 years ago
comment:74 by , 7 years ago
OK Solved one problem (#70) on to the next.
As described before using WP5.1 to edit a dataset (HISTDQ67) results in the dataset vanishing
system: R338 OS4 debug kernel; FAT32.IFS /monitor WP copies the dataset to HISTDQ67.BK! and at the end of editing deletes the original and MOVES HISTDQ67.BK! to HISTDQ67. Except that the log shows the MOVE ending with code 2 (which I assume means it didnt work).
this is also 100% consistent.
comment:75 by , 7 years ago
Yes, HISTDQ67.BK! seems to be deleted before MOVE'ing it to HISTDQ67. But all I see before MOVE'ing is CLOSE'ing HISTDQ67.BK!. The log contains no info when it was opened and what operations have been made next. So, please take a full log (ZIP it, if needed).
by , 7 years ago
comment:76 by , 7 years ago
(I got the interface working again but not sure how!)
wp02.zip is a large trace with both the open and the close (I checked)
I also got an error 6... (but no trap)
comment:77 by , 7 years ago
What is strange in this log: wp02.zip is that I see closing the HISTDQ67.BK! file two times. But it is opened one time only! Are you sure you got a full log? Please, check your log for having the same number of OPEN's like the number of CLOSE's. I see the HISTDQ67 is moved to HISTDQ67.BK! first. Then HISTDQ67.BK! is closed, then HISTDQ67 is truncated to a zero size. And later, HISTDQ67.BK! is closed again for the 2nd time. So, it should be opened for 2nd time earlier.
Also, I don't see any function here returning ERROR_INVALID_HANDLE == 6. Again, the log beginning is cut out? 300 KB log is not so big indeed. If you cannot upload the log here, you could try sending it to me via email.
PS: Also, please clarify what do you mean by "file vanishing". Is it zero-sized, or is it zero-filled?
comment:78 by , 7 years ago
1) that was a complete log. Not sure what I can do to confirm that. I could open something else to give a marker?
2) I can give you a something to compare with by doing the same using R290 in which everything works fine.
3) By "file vanishing" I mean that there is no entry in the FAT directory. So DIR does not show it. What happens to the contents I couldnt say.
I will do 2 runs (as suggested in (1) and (2) ) and we can see what they show
[I think the error 6 appeared after I had extracted the log (which I did quickly to avoid the start being over-written)
by , 7 years ago
comment:79 by , 7 years ago
As above:
WP03.ZIP contains two files with identical runs Both are using OS4 debug kernel, with /monitor specified for FAT32.IFS and F32MON called in the session
1) wp03a.txt FAT32 version R338
the data starts at line 2266 of the log where you can see CD to d\notes\os2
so far as I can tell all the data is present.
At the end of the session DIR HISTDQ67.* did NOT show the file I had been editing
2) wp0ba.txt FAT32 version R290
the data starts at line 3557 of the log where you can see CD to d\notes\os2
so far as I can tell all the data is present.
At the end of the session DIR HISTDQ67.* did show the file I had been editing
(there was an oddity at the end which you can see from the last line of the log. F32MON ended with a black screen telling me there was a chaining error in the FAT32 data and when I returned from that put up the devfs message you can see on the last line.
I have not see this before
I rebooted to a different system and did chkdsk which indeed showed bad clusters. )
by , 7 years ago
comment:80 by , 7 years ago
I realised that I had left a SET DELDIR in the AUTOEXEC for the call to DOS. I have REMed that out and repeated the test with the same effect (except that the operation of DELDITR was confusing the trace)
WP04.ZIP contains two files with identical runs Both are using OS4 debug kernel, with /monitor specified for FAT32.IFS and F32MON called in the session
1) wp04a.txt FAT32 version R338
all the data is present.
At the end of the session DIR HISTDQ67.* did NOT show the file I had been editing
2) wp04b.txt FAT32 version R290
all the data is present.
At the end of the session DIR HISTDQ67.* did show the file I had been editing
Looking at the end of the traces: for R338 it is very clear that the last operation on HISTDQ67 is DELETE (line 4929), while for R290 it is CLOSE (line 5219)
comment:81 by , 7 years ago
Thanks for the logs. But as you say that the issue is missing with r290, can you try revisions within r290 .. r338 range? I.e., you try (290 + 338) / 2 == 314. So, if the issue is present in r314, try (290 + 314) / 2 == 302. If the issue is missing in r314, you try (314 + 338) / 2 == 326. And so on. So, iterating this way, you can quickly determine, between which consecutive revisions this issue is appeared. A method of bisections :) It will require 10 tries from you, or so. You can look at ftp://osfree.org/upload/fat32/ for builds archive.
comment:82 by , 7 years ago
good thinking. Actually quicker because I first detected this in R326. Will experiment and give you the results
comment:88 by , 7 years ago
Ok, thanks. So this was the modification r317 to ModifyDirectory function I made for exFAT, but it seems to break FAT32 somehow. Need to look at it closer now.
comment:89 by , 7 years ago
Now please, try ftp://osfree.org/upload/fat32/test/bl6.zip. Copy it over r317. Will it work?
comment:91 by , 7 years ago
Hm... Are you sure? Now please, try bl7.zip, from the same place. It is the updated last version r338 with the same changes. Also, please take a log output of the same test case (when your file is deleted/vanished).
by , 7 years ago
comment:92 by , 7 years ago
yes I am sure :-)
bl7 also fails. I have attached the log in bl05.zip
close to the end I see delete of the file HISTDQ67 succeeded followed by a MOVE of HISTDQ67.BK! to HISTDQ67 which gets a code 2 (failure I assume)
The word perfect session (trying to write the dataset back and exit) got an error 6 and stopped.
After the log I gave it the exit command again with no write and it did exit ; at that point I checked and the HISTDQ67 dataset is not present.
comment:93 by , 7 years ago
Yes it deletes HISTDQ67, and tries to rename a backup called HISTDQ67.BK! back to HISTDQ67 and fails (it seems like HISTDQ67.BK! not found). It should be a RENAME operation, but I don't see calling ModifyDirectory with MODIFY_DIR_RENAME parameter. It does RENAME in the beginning, when renaming HISTDQ67 to HISTDQ67.BK! (a backup copy), then creates an empty HISTDQ67. But in the end, it attempts to rename HISTDQ67.BK! back to HISTDQ67, and now without the RENAME flag, which is strange.
Ok, I added more log messages -- please test bl8.zip over bl7.zip (I'll need a log).
comment:94 by , 7 years ago
It seems, I found another error in FS_MOVE code, so, please, skip bl8.zip and use bl9.zip already.
by , 7 years ago
comment:95 by , 7 years ago
OK I ran that; it still failed in the same way (but no error 6) - that is the dataset being edited HISTDQ67 was deleted.
WP09.ZIP is the log
comment:96 by , 7 years ago
According to your log, HISTDQ67.BK! is successfully closed, and then HISTDQ67 is explicitly deleted. I no more see FS_MOVE failing to rename HISTDQ67.BK! to HISTDQ67. So, the error looks to be fixed. The only thing I don't understand is why it deletes HISTDQ67 in the end.
PS: HISTDQ67.BK! should still be on the disk -- please check that (or it deletes it later, but I don't see that, because the log was closed, and it is not complete).
comment:97 by , 7 years ago
HISTDQ67.BL! is NOT on the disk (or at least. not in the FAT directory)
The log was taken AFTER Wordperfect had completed its work and returned to the DOS prompt, and the log had gone quiet, so no activities were pending so there cannot be a later delete of BK! because WP is not called again.
The error is the delete of HISTDQ67; I am fingering FAT32 as the culprit since up to R316 the process works correctly and the end result is that HISTDQ67 is NOT deleted but .BK! is, and the only difference is the version of FAT32.
Shall I run a full log with the R316 version?
comment:98 by , 7 years ago
I did an experiment using a second window to look at the directory while WP was editing the file.
While the file is being edited the xxx.bk! does not exist.
It seems to be created as part of the writeback process; at the point I managed to detect the bk! file it was full length and the original (HISTDQ67) existed but was zero length (presumably being written).
comment:99 by , 7 years ago
Looking at the file lengths the BK! file is NOT copied back to the original; it appears to be a safety copy and has the same length as the unedited version. The file that has been edited is I suppose recreated from wherever WP holds a file in progress.
comment:100 by , 7 years ago
Looking at all the logs I think the process used by WP is:
While editing put the result on internal WP temporaries (in the WP directory, which in my case is also on d:)
when exiting ask the user whether to save or leave
If leaving, delete the temporaries and exit
If saving, copy the original A to A.BK! (this is a safety feature. If the system dies at this point the original is available in BK!)
(uncertain) clear or recreate the original file and copy to it from the temporaries
delete the BK! and delete the temporaries and exit
In the cases where the editing process is broken in that the original dataset is not available after exiting WP the logs show an explicit delete of A instead of BK!. As a total guess I wonder if WP is getting a signal that there was an error in creating the new version of the file which is why it is deleting it?
This would explain why the file is deleted but NOT why the BK! is also deleted (and none of the logs show both deletes).
The fact remains that up to version R316 the process works fine.
comment:101 by , 7 years ago
I realised that the fact that the word perfect program and the datasets it uses for the intermediate stages are ALSO on the FAT32 volume may be confusing the issue and could easily be the cause of the problem(s).
I cannot easily move WP to a different volume as that means reinstallation (from 3.5 discs!) so I have moved the data to a JFS volume
In an initial test I did indeed get funny results, including an error 6... and different on different JFS volumes.
So I will run a logging run with the data on a JFS and WP on FAT32 to see what problems show up and post result here (wth a run using R290 for comparison)
by , 7 years ago
comment:102 by , 7 years ago
That did not work so well! Various errors occurred when Was editing on a JFS volume so I decided not to muddy the waters.
In case it makes a difference I repeated earlier tests. WP10.ZIP contains 2 logs
1) R290 OS4 debug F32mon on; /monitor
WP editing data from D: without a problem: WP10b .txt
2) R338 (bl7 version) OS4 debug F32mon on; /monitor
WP editing data from D: attempt to save ended with error 6: WP10c.txt
I can see a very suspicious sequence in the log
a) move source to source.BK!
b) delete source
c) move source.BK! to source
the last move gets a code 2. (Obviously a failure; what does it mean?)
So not surprisingly end result is that the dataset source is deleted from the FAT directory.
The version that works has the initial move to BK! but not the others
I see no clue why Wordperfect decided to do that.
by , 7 years ago
by , 7 years ago
comment:103 by , 7 years ago
To declutter the logs I have now succeeded in moving the wordperfect program to a different (FAT16) partition.
both runs in OS4 debug kernel wit .monitor for FAT32.IFS and F32mon running
NO1.TXT is the log of running the BL9 version of FAT32. Editing D\NOTES\OS2\HISTDQ67 results in the FAT entry being deleted (DELETE command issued)
N02.TXT is the of exactly the same circumstances using R290 where the edit succeeds and the dataset is not deleted.
In some way FAT32 must be signalling some failure to WP.
comment:104 by , 7 years ago
One more experiment
I copied the dataset which I have been editing on the FAT32 partition onto a FAT16 partition. WP acting on the dataset on the FAt16 partition could repeatedly edit and save it without any problem. Clearly the issue has to be with the FAT32.IFS implementation.
comment:105 by , 7 years ago
Please take a log of situation like in your wp10.zip log, i.e., like this:
P:4b T:7e D:f5b T:19:26 FS_MOVE D:\D\NOTES\OS2\HISTDQ67.BK! to D:\D\NOTES\OS2\HISTDQ67 P:4b T:7e D:f5b T:19:102 FS_MOVE returned 2
I'm interested to see the log of moving HISTDQ67.BK! back to the original, and failing. And, please, use the latest binaries (bl9.zip, and not bl7.zip). I need the extra debug info.
PS: FAT16 differs from FAT32 only in that the root directory is a special case (It cannot grow, and it resides in the reserved data area, it has no clusters assigned). But as far as I can see, your file is not in the root directory.
comment:106 by , 7 years ago
PPS: What do you mean by using FAT16 partition? Did you added the "/fat" switch to fat32.ifs, or just using IBM's FAT driver? If the latter, then not interesting.
comment:107 by , 7 years ago
I mean I am using the IBM FAT driver (OS2 driver) - the interest is that it removes any lingering doubt that it might be a defect in WordPerfect.
by , 7 years ago
comment:108 by , 7 years ago
N03.txt is the log of r338 with bl9 on top.
TWO tried at editing the dataset; first time succeeds, the second time while it apparently works (no errors shown) it quietly deletes the original dataset. This effect appears to be repeatable.
I do not see any "returned 2" but I cannot force that to happen.
comment:109 by , 7 years ago
I do not see any "returned 2" but I cannot force that to happen.
Ok, it seems like bl9.zip fixed that. Also, I see after deleting the original dataset:
1455 P:4b T:7f D:a64 T:4:811 FS_FINDFIRST for D:\D\NOTES\OS2\HISTD*.* attr 37, Level 1, cbData 278, MaxEntries 1 1456 P:4b T:7f D:a64 T:4:828 FS_FINDFIRST returned 0 (1 entries)
So, it finds one file of this mask, which is HISTDQ67.BK!. So, it seems, it closes HISTDQ67.BK!, and deleted HISTDQ67, but not vice versa. No ideas why. Can you check if HISTDQ67.BK! still remained in place?
comment:110 by , 7 years ago
I think, it deletes HISTDQ67 to subsequently move a HISTDQ67.BK! backup to HISTDQ67, but doesn't do that, for some reason.
comment:111 by , 7 years ago
I have a hypothesis, what's wrong (please test bl10.zip, at the ftp). Will it fix the problem with deleting HISTDQ67?
by , 7 years ago
comment:112 by , 7 years ago
bl10.zip unzipped on top of R338: log N04
the usual test fails first time, and ends with HISTDQ67 deleted (as the log shows)
comment:113 by , 7 years ago
just to remove another variable I copied the dataset to the root of the drive and attempting to edit it with WP produced the same result - after apparently saving it OK the dataset had been deleted from the FAT directory.
comment:114 by , 7 years ago
whatever the change was in version BL10 it has made the result of using WP5.1 to edit a datase 100% consistent. The dataset gets deleted at the end of editing. I tried with a totally new very short dataset; same result.
comment:115 by , 7 years ago
2landb:
Does HISTDQ67.BK! remains on disk after HISTDQ67 is deleted? Can you give me the WP5 distribution, so I can try to reproduce your case on my machine?
PS: Sorry for being silent so much time (I had some problems at work and with other projects)
comment:116 by , 7 years ago
comment:117 by , 7 years ago
1) no; neither HISTDQ67 nor HISTDQ67.BK! remain on disk (ie in the FAT directory)
2) AFAIR the error that appears with r317 is deleting the original file. I think the Error 6 is a side issue.
comment:118 by , 7 years ago
the source distribution is of course on diskettes. I could try putting them on a CD and posting to you. I may be able to email it depending on how large the distro is. I will look tomorrow
comment:119 by , 7 years ago
the WP51 directory is 5Mb and seems self contained (has all its own DLLs). I will ZIP that up and email it to you directly (not via this bugtracker)
comment:121 by , 7 years ago
I have tested r349 with bith ecs22 and arcaos and it seems to work fine : specifically I cannot recreate the reported problem of the directory entry vanishing
comment:122 by , 5 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
It seems fixed then. Lets close this ticket.
Use SVN rev >= 327 as SVN rev 327 rolls back a change that led to the trap that you are observing.